Do you want to know top search engine bots and how they work? If your aim of opening this web page is that, you are in the right place. Today, I will show you the names of top search engine bots. But before we get started, I like to briefly talk about what search engine bots are all about.
For example, the work of a web crawler bot is like someone who goes through books in a disorganized library and puts them together so that anyone who visits the library can easily find the information they need. For bots to categorize and sort the websites by niche, they have to read the title, summary, and some of the internal text of each website to figure out what it’s about.
You may also see our guide on how to create metadata for your content (blog & website).
The internet is not composed of physical piles of books, and that makes it hard to tell if all the necessary information has been indexed properly, or if the majority of it is being overlooked. In order for all the relevant information on the website to be shown on search engines, web crawler bots focus on the website homepage and then follow hyperlinks from those pages to other pages, then follow hyperlinks from those other pages to additional pages, and so on.
In conclusion, for a website to be indexed, bots need to crawl it, however, there are bots that are malicious to add viruses to websites. Malicious bots can be blocked for a website’s security but crawler bots don’t have to be blocked if you want your website pages to rank and get indexed on search engines.

Let us start discussing top search engine bots.
Top search engine bots in the world
Below are the top bots from the major search engines in the world.
- Google: Googlebot
- Yahoo! Search: Slurp
- Baidu: Baiduspider
- Bing: Bingbot
- Exalead: ExaBot
- DuckDuckGo: DuckDuckBot
- Yandex: YandexBot
There are also many other web crawler bots, some of which are not associated with any search engine. Now, let us proceed to see how search engine bots work.
How do search engine bots work?
The Internet is constantly changing and expanding as it is not possible to know how many total web pages there are on the Internet, and as such, web crawler bots start from the home page or a list of known URLs. They crawl the web pages at those URLs first. As they crawl those pages, they will find hyperlinks to other URLs, and they add those to the list of pages to crawl next.
Given the vast number of web pages on the Internet that could be indexed for search, this process could go on almost indefinitely. However, a web crawler will follow certain policies that make it more selective about which pages to crawl, in what order to crawl them, and how often they should crawl them again to check for content updates.
Let me show you some policies that search engine bots follow in crawling web pages on search engine results.
1. The relative importance of each webpage: Most web crawlers don’t crawl the entire publicly available Internet and aren’t intended to; instead they decide which pages to crawl first based on the number of other pages that link to that page, amount of visitors that page gets, and other factors that signify the page’s likelihood of containing important information.
The idea is that a webpage that is cited by a lot of other web pages and gets a lot of visitors is likely to contain high-quality, authoritative information, so it’s important that search engine bots have to index it first just as a library might make sure to keep plenty of copies of a book that gets checked out by lots of people in a reachable place.
2. Revisiting webpages: Content on the Web is continually being updated, removed, or moved to new locations. Web crawlers will periodically need to revisit pages to make sure the latest version of the content is indexed.
3. Robots.txt requirements: Web crawlers also decide which pages to crawl based on the robots.txt protocol. Before crawling a webpage, they will check the robots.txt file hosted by that page’s web server. A robots.txt file is a text file that specifies the rules for any bots accessing the hosted website or application.
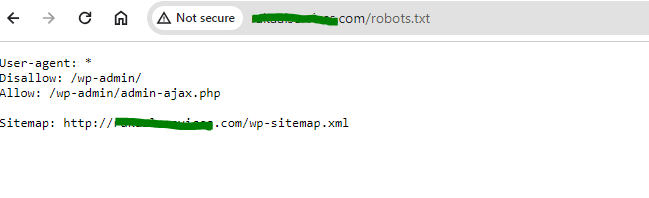
These rules define which pages the bots can crawl, and which links they can follow. If you want to view the robots.txt content of a website, type “robots.txt” at the front of a complete website url, for example,www.fastknowers.com/robots.txt/
All these factors are weighted differently within the proprietary algorithms that each search engine builds into their bots. Though, web crawlers from different search engines will behave slightly differently, but the end goal is the same which is to download and index content from web pages.
Conclusion
Bots help search engine to index pages on a website. As we told you earlier in this article, there are two types of bots; search engine bots and malicious bots. You need search engine bots on your website. And I hope this article has shown you top search engine bots and how they work. You may see our guide on what do viruses do to a website.
If you know that this article has helped you, please share it with other and subscribe to my YouTube channel for more updates. You can also like my Facebook page.





Thank you for this update my SEO expert. This dude himself is SEO organized 😊😊
Hello dear sir. Thank you for this inspiration guide. I learned some new things from this article.
There’s question that I want to ask but it does not relate to this topic. I am sorry for asking off topic question here. The question that what is the name of advertising company or how one can run ads on search engine bots you listed in this article? For example, if you want to run on Google, you visit Google ads. So what is the one for Opera Mini, Yandex, Bing, etc.
Thank you for your answer.